SpringCloud 整合 Sleuth 实现服务链路追踪,实战讲解!
一、背景介绍
在之前的文章中,我们陆续介绍了 Spring Cloud 技术体系中的 Eureka、Ribbon、Fegin、Hystrix、Config、Zuul 等核心组件的作用和使用方式。
实际上,通过这几个组件可以搭建一套基础的微服务架构系统来实现我们的业务需求了。
随着业务的发展,微服务的数量会越来越多,各微服务间的调用关系也变得越来越错综复杂,可能一个业务接口的请求,要经过好几个微服务的调用处理,如果某个微服务的调用处理失败了,接口的请求将会以失败告终。最关键的是,在错中复杂的微服务环境下,如何排查请求的错误原因,对于开发者而言,如果没有一个快速的排查工具,将如大海捞针。
在这样的背景下,分布式系统调用跟踪服务诞生了。
今天通过这篇文章,我们一起来了解一下 Spring Cloud 技术体系中一个重要的服务链路追踪组件 Sleuth。
二、Sleuth 简介
Spring Cloud Sleuth 是 Spring Cloud 生态系统中的一个分布式追踪解决方案。
通过集成 Sleuth,开发人员可以追踪一个用户请求在多个微服务间传播时经过的所有服务调用,并生成详细的请求跟踪信息,从而快速定位问题出现的具体服务和接口。不仅如此,还可以了解每个服务的性能情况,如调用耗时、调用次数等,进而进行性能优化。
Sleuth 是如何实现这一点的呢?
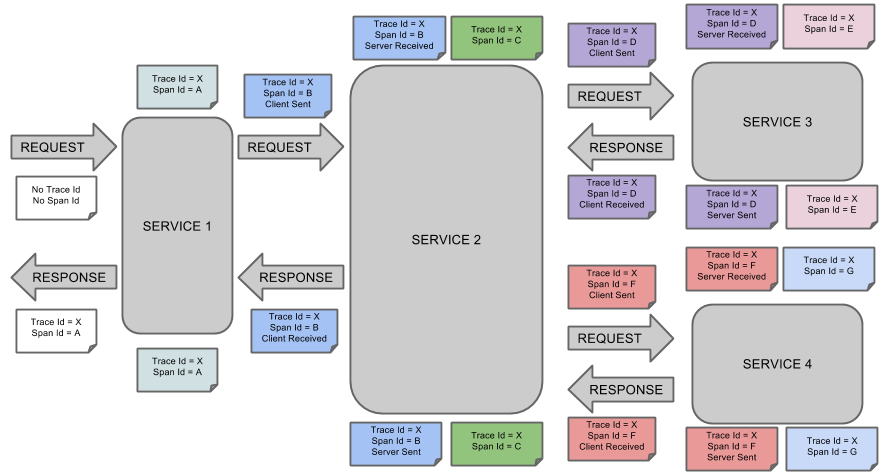
在 Sleuth 中有个核心组件:Tracer。当一个请求到来时,Tracer 会在当前服务日志里面生成一个 Trace ID 和一个 Span ID,并将它们传递给下一个服务节点。
其中 TraceID 和 SpanID 含义如下:
- TraceID:用于标记一条完整的请求链路,会作为唯一标记值在各个微服务之间传递,以便跟踪请求链路上调用过的所有服务
- SpanID:用于标记一个请求在一个服务节点的处理过程,每个Span都包含了开始时间、结束时间、Span ID、父Span ID、Span名称、Span标签等信息,通过它可以快速定位某个方法的执行时间以及相关的描述信息;
Sleuth 处理流程可以用如下图来简要概括。
除此之外,Sleuth 还可以与 Zipkin、ELK 等分布式跟踪系统集成,以便更加直观的查询服务的实际调用情况。
下面我们通过具体的例子,看看如何使用 Sleuth 来实现服务链路跟踪。
三、方案实践
通过 Spring Cloud Sleuth 来实现服务链路跟踪也非常的简单,通过以下三步骤即可完成。
3.1、添加依赖包
根据eureka-consumer-fegin复制一个服务消费者工程,命名为eureka-consumer-sleuth-1,并在pom.xml中引入 sleuth 依赖包,示例如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>3.2、添加配置文件
和服务消费者一样,在application.properties配置文件中添加服务注册中心地址。
spring.application.name=eureka-consumer-sleuth-1
server.port=9013
# 设置与Eureka Server交互的地址,多个地址可使用【,】分隔
eureka.client.serviceUrl.defaultZone=http://localhost:8001/eureka/3.3、创建启动类
接着,创建服务启动类,并实现一个/trace-1接口,用于测试服务链路追踪是否符合预期。
@EnableFeignClients
@EnableDiscoveryClient
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}在/trace-1接口中添加相关的调用日志。
@RestController
public class HelloController {
private static final Logger LOGGER = LoggerFactory.getLogger(HelloController.class);
@Autowired
private RpcService rpcService;
/**
* 发起远程调用测试
* @return
*/
@GetMapping("/trace-1")
public String trace() {
LOGGER.info("trace-1,准备向trace-2发起请求...");
String result = rpcService.hello();
LOGGER.info("trace-1,收到trace-2返回结果:" + result);
return "trace-1,收到返回的信息:" + result;
}
}3.4、服务测试
然后,根据上面的案例,再创建一个eureka-consumer-sleuth-2工程并实现一个/trace-2接口,内容如下:
@RestController
public class HelloController {
private static final Logger LOGGER = LoggerFactory.getLogger(HelloController.class);
/**
* 发起远程调用测试
* @return
*/
@GetMapping("/trace-2")
public String trace() {
LOGGER.info("trace-2,收到请求");
return "hello,我是trace-2!";
}
}最后,将eureka-consumer-sleuth-1、eureka-consumer-sleuth-2以及服务注册中心启动起来。
在浏览器上访问http://localhost:9013/trace-1,同时观察服务控制台的日志内容。不出意外的话,会看到类似如下的内容。
-- trace-1 服务日志
2024-10-15 18:02:15.850 INFO [eureka-consumer-sleuth-1,58a2cabc2d29bcf6,58a2cabc2d29bcf6,false] 26782 --- [nio-9013-exec-5] c.e.c.e.consumer.web.HelloController : trace-1,准备向trace-2发起请求...
2024-10-15 18:02:15.864 INFO [eureka-consumer-sleuth-1,58a2cabc2d29bcf6,58a2cabc2d29bcf6,false] 26782 --- [nio-9013-exec-5] c.e.c.e.consumer.web.HelloController : trace-1,收到trace-2返回结果:hello,我是trace-2!
-- trace-2 服务日志
2024-10-15 18:02:15.860 INFO [eureka-consumer-sleuth-2,58a2cabc2d29bcf6,dd77986d1c5cf706,false] 26731 --- [nio-9014-exec-5] c.e.c.e.consumer.web.HelloController : trace-2,收到请求从上面的输出内容中可以看到,与普通的日志相比,多了一些比如 [trace-1,f410ab57afd5c145,a9f2118fa2019684,false]的日志信息,这些元素正是实现分布式服务跟踪的重要组成部分,它们每个值的含义如下:
- 第一个值:
eureka-consumer-sleuth-1,它记录的是服务应用的名称。 - 第二个值:
58a2cabc2d29bcf6,是 Spring Cloud Sleuth 生成的一个 Trace ID,它用来标识一条请求链路。一条请求链路中会包含一个Trace ID,多个Span ID。 - 第三个值:
dd77986d1c5cf706,是 Spring Cloud Sleuth 生成的 Span ID,它表示一个基本的工作单元,比如:发送一个 HTTP 请求,不同的服务值会有所不同。 - 第四个值:
false,表示是否要将该信息输出到 Zipkin 等服务跟踪系统中来收集和展示,目前没有集成,所以为false。
从日志中可以清晰的看到,虽然trace-1和trace-2分别属于不同的服务,但是它们输出的 Trace ID 是一致的,通过它可以查询到一个请求中调用到的所有服务以及相关的处理过程,对于快速定位服务中出现的问题至关重要。
四、整合 ZipKin
在上文中我们提到过,可以利用 sleuth 来排查每个服务节点的请求耗时,但是通过人工分析日志的方式会非常鸡肋。对于这类问题,Zipkin 就可以轻松帮我们解决掉。
Zipkin 是一个开放源代码分布式的跟踪系统,由 Twitter 公司开发。我们可以使用它来收集各个服务器上请求链路的跟踪数据,快速排查服务请求中出现的延迟升高问题并找出系统性能瓶颈的根源。
除了面向开发者提供的 API 接口之外,它也提供了方便的 UI 组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,比如:可以查询某段时间内各用户请求的处理时间等。
Zipkin 的处理流程可以用如下图来描述。
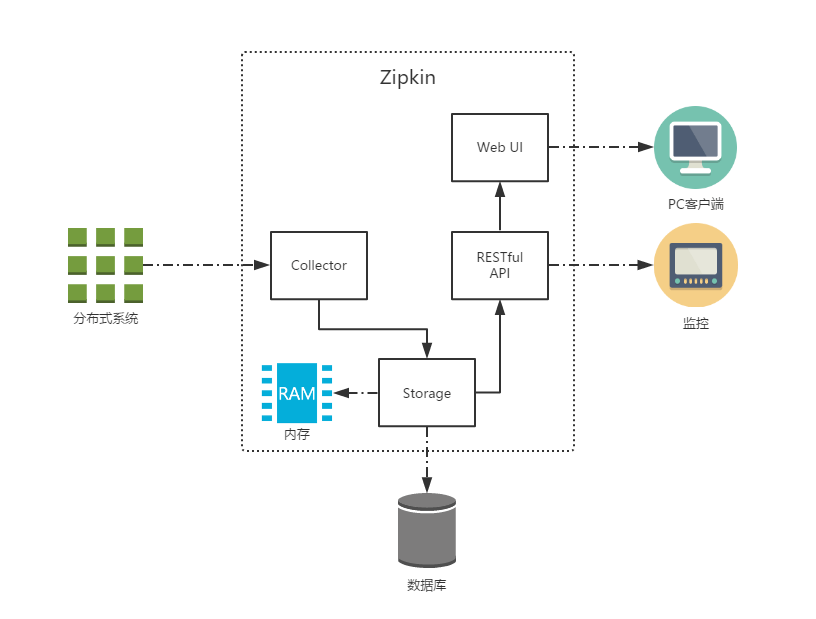
Zipkin 还支持多种数据存储方式,例如:In-Memory、MySql、Cassandra 以及Elasticsearch,生产环境建议采用 Elasticsearch。
下面我们通过具体的例子,看看如何使用 Zipkin 来搜集服务链路日志,为了便于演示,本文直接采用 In-Memory 方式进行存储。
4.1、搭建 Zipkin Server
搭建 Zipkin Server 非常简单,只需如下三步即可完成。
4.1.1、创建 Zipkin Server 工程
首先创建一个 Spring Boot 工程,命名为zipkin-server,并在pom.xml中引入 zipkin 依赖包,示例如下:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.4.RELEASE</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Edgware.SR3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>4.1.2、添加配置文件
在application.properties中做一些简单配置即可,内容如下:
spring.application.name=zipkin-server
server.port=90204.1.3、创建启动类
创建服务启动类,并添加@EnableZipkinServer注解,以便启动 Zipkin 相关服务。
@EnableZipkinServer
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}4.2、客户端添加 Zipkin 支持
在eureka-consumer-sleuth-1、eureka-consumer-sleuth-2工程中,添加 Zipkin 客户端依赖包,内容如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>接着,在application.properties配置文件中添加 Zipkin 支持,内容如下:
# 添加Zipkin Server的配置信息
spring.zipkin.base-url=http://localhost:9020
# 设置采样比例为100%
spring.sleuth.sampler.percentage=1.0默认情况下,sleuth 的采集比例为0.1,因此当发起请求的时候,日志不会立刻同步到 zipkin 中,测试的时候可以提高采集比例,以便观察服务追踪情况。
4.3、服务测试
最后,将zipkin-server、eureka-consumer-sleuth-1、eureka-consumer-sleuth-2以及服务注册中心启动起来。
在浏览器上访问http://localhost:9020/地址,不出意外的话,会看到类似如下的界面。
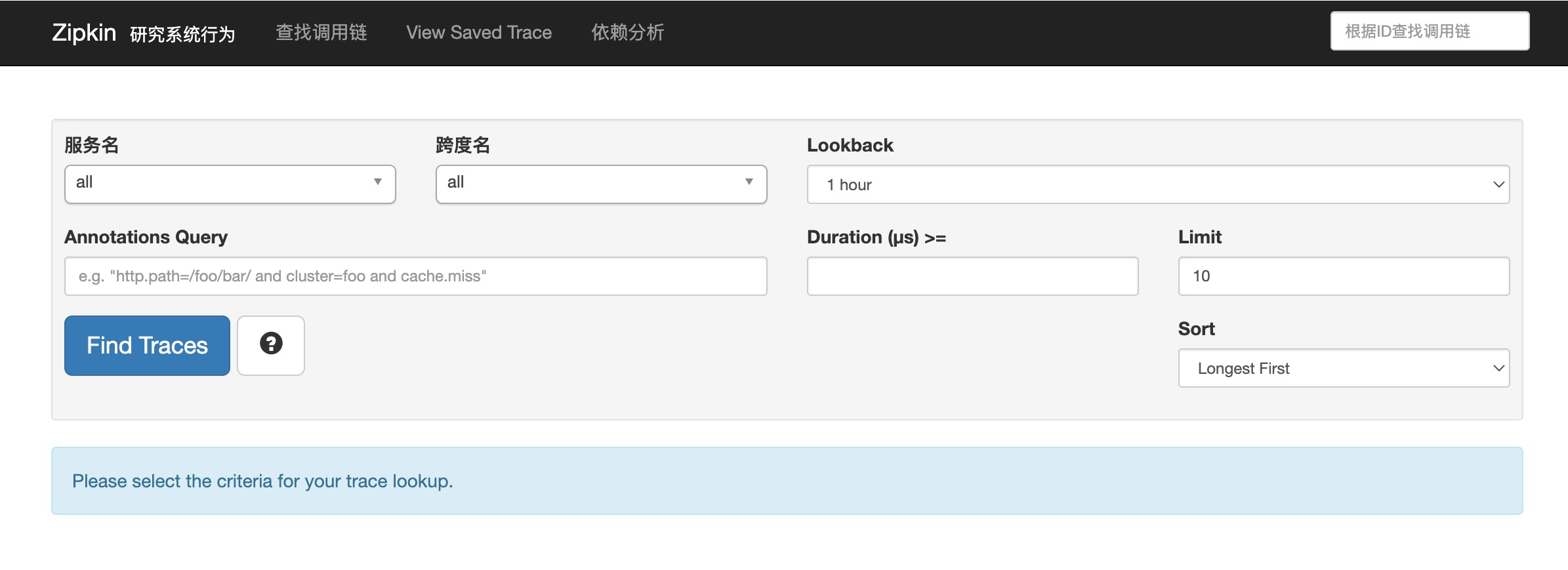
这是 zipkin 提供的 ui 界面。
接着,在浏览器上再次访问http://localhost:9013/trace-1。
此时 sleuth 生存的服务追踪日志会同步到 zipkin 中。
点击Find Traces按钮,会查询到同步的服务请求链路日志。
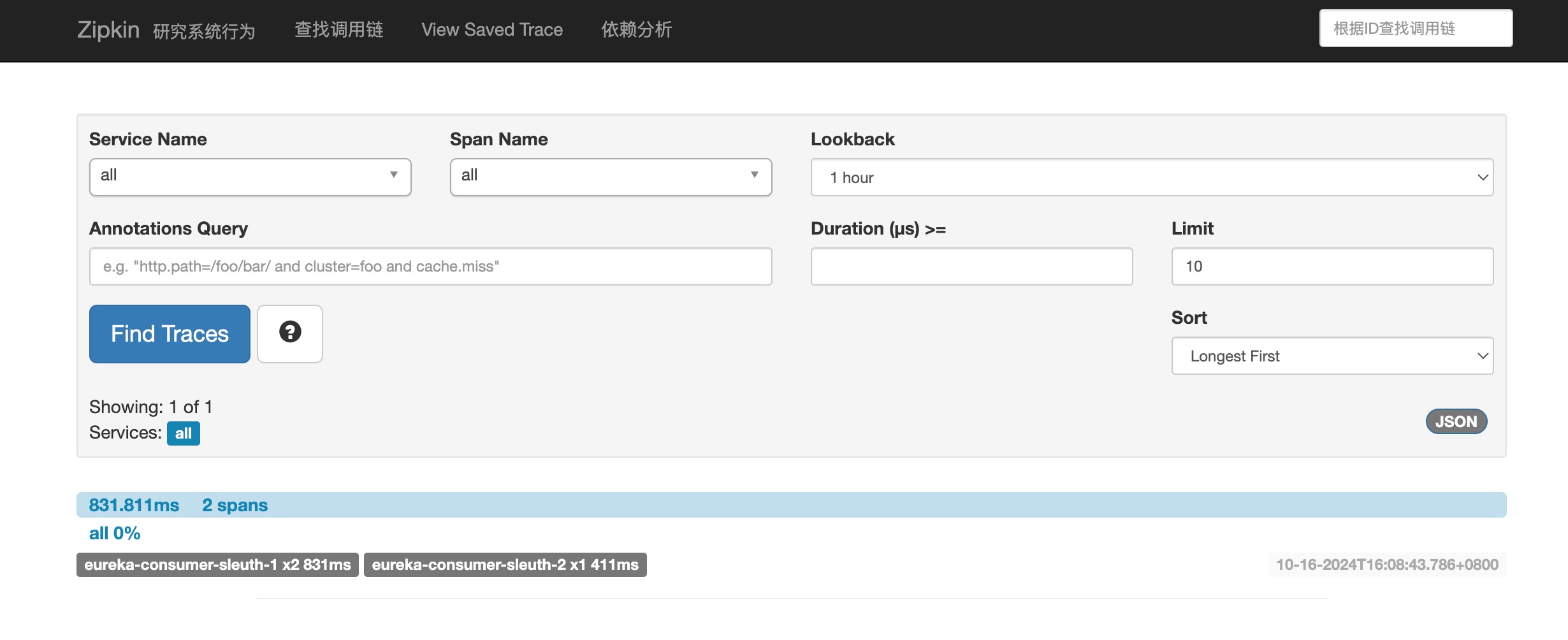
点击请求链路,进入详情可以查询请求经过的服务路线。
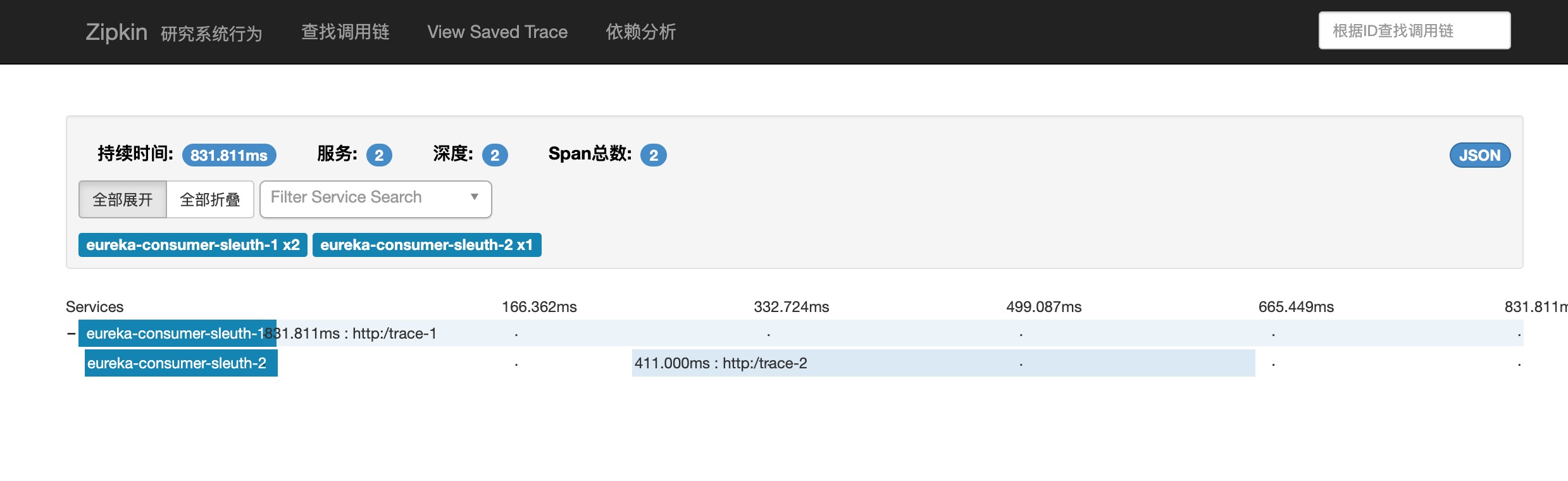
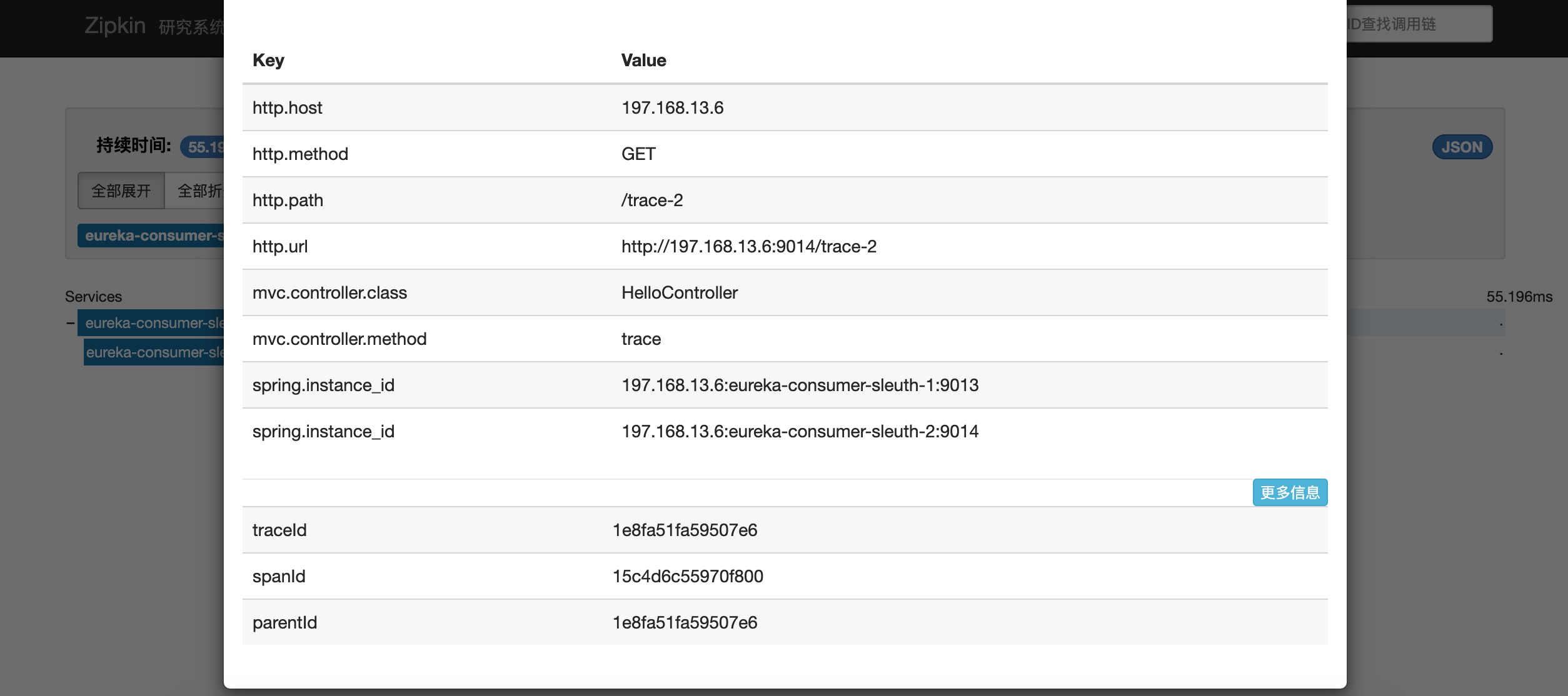
点击请求服务,可以查询具体服务的类和方法以及对应的耗时。
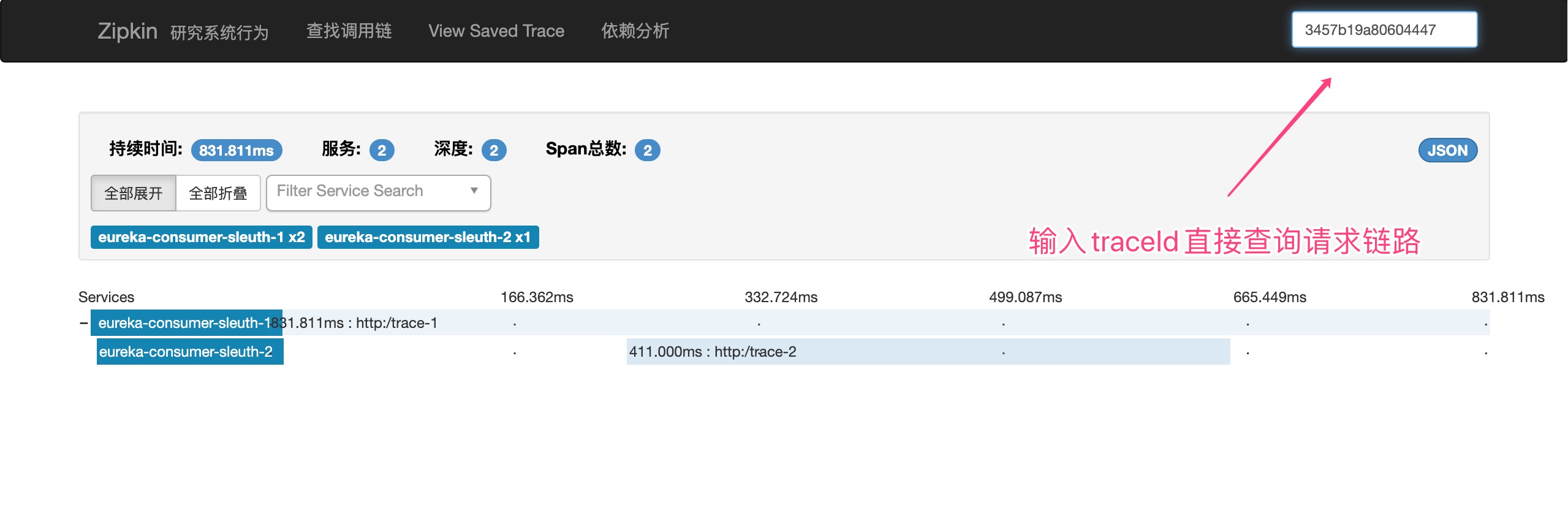
也可以通过traceId直接查询请求链路。
4.4、异步收集服务日志
如果日志流量很大,也可以将 Sleuth 生成的服务日志以异步的形式同步到 MQ 中,然后转发到 Zipkin 服务器以降低负载。
大体实现思路如下!
4.4.1、客户端调整方案
首先,添加spring-cloud-sleuth-stream相关的组件,示例如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>然后,在配置文件中添加 rabbitMQ 相关的配置信息,同时去掉spring.zipkin.base-url参数,示例如下:
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=admin
spring.rabbitmq.password=admin4.4.2、服务端调整方案
与客户端类似,在添加pring-cloud-sleuth-zipkin-stream相关的组件,示例如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>然后,在配置文件中添加 rabbitMQ 相关的配置信息,内容如下:
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=admin
spring.rabbitmq.password=admin当收到请求之后,sleuth会将服务日志发送到 rabbitMQ 中,zipkin会从 rabbitMQ 中采集相关的服务日志进行分析。
五、小结
最后总结一下,Sleuth + Zipkin 组合可以很好帮助我们解决在错中复杂的微服务环境下,快速定位服务请求中出现的性能瓶颈以及异常问题。掌握其用法,对于排查请求中的出现问题,帮助巨大。
六、参考
1.http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html
作者:潘志的技术笔记
出处:https://pzblog.cn/
版权归作者所有,转载请注明出处
