Java 对象在内存中的创建过程详解
一、背景介绍
在之前的文章中,我们介绍了类加载的过程和 JVM 内存布局相关的知识。本篇我们综合之前的知识,结合代码一起推演一下对象的真实创建过程,以及对象创建完成之后在 JVM 中是如何保存的。
二、对象的创建
在 Java 中,创建对象的方式有很多种,比如最常见的通过new xxx()来创建一个对象,通过反射Class.forName(xxx).newInstance()来创建对象等。其实无论是哪种创建方式,JVM 底层的执行过程是一样的。
对象的创建过程,可以用如下图来简要概括。

创建对象大致分为 5 个步骤:
- 1.检查类是否加载,如果没有就先执行类的加载
- 2.分配内存
- 3.初始化零值
- 4.设置头对象
- 5.执行初始化方法,例如构造方法等
下面我们一起来看下每个步骤具体的工作内容。
2.1、类加载检查
当需要创建一个类的实例对象时,比如通过new xxx()方式,虚拟机首先会去检查这个类是否在常量池中能定位到一个类的符号引用,并且检查这个符号引用代表的类是否已经被加载、解析和初始化,如果没有,那么必须先执行类的加载流程;如果已经加载过了,会在堆区有一个类的 class 对象,方法区会有类的相关元数据信息。
为什么在对象创建时,需要有这一个检查判断?
主要原因在于:类的加载,通常都是懒加载,只有当使用类的时候才会加载,所以先要有这个判断流程。
关于类的加载过程,在之前的文章中已经有所介绍,有兴趣的朋友可以翻看之前的文章。
2.2、分配内存
类加载成功后,虚拟机就能够确定对象的大小了,此时虚拟机会在堆内存中划分一块对象大小的内存空间出来,分配给新生对象。
虚拟机如何在堆中分配内存的呢?
主要有两种方式:
- 1.指针碰撞法
- 2.空闲列表法
下面我们一起来看看相关的内存分配方式。
2.2.1、指针碰撞法
如果内存是规整的,那么虚拟机将采用指针碰撞法来为对象分配内存。
指针碰撞法,简单的说就是所有用过的内存在一边,空闲的内存在另一边,中间放着一个指针作为分界点的指示器,分配内存时会把指针向空闲一方挪动一段,直到能容纳对象大小的位置。
如果垃圾收集器选择的是 Serial、ParNew 这种基于压缩算法的,虚拟机会采用这种分配方式。
2.2.2、空闲列表法
如果内存不是规整的,已使用的内存和未使用的内存相互交错,那么虚拟机将采用空闲列表法来为对象分配内存。
空闲列表法,简单的说就是在虚拟机内部维护了一个列表,会记录哪些内存块是可用的,在分配的时候会从列表中找到一块能容纳对象大小的空间,划分给对象实例,并更新列表上的内容。
如果垃圾收集器选择的是 CMS 这种基于标记-清除算法的,虚拟机会采用这种分配方式。
2.2.3、内存分配安全问题
我们知道,虚拟机是支持多个线程同时分配内存的,是否会有线程安全的问题呢?
答案是:肯定存在的。比如用指针碰撞法时,虚拟机正在给对象 A 分配内存,但指针还没来及修改,此时又有一个线程给对象 B 分配内存,同时使用了原来的指针来分配,最后的结果就是这个区域只分配来一个对象,另一个对象被覆盖了。
针对内存分配时存在的线程安全问题,虚拟机采用了两种方式来进行处理:
- CAS+重试机制:通过 CAS 操作移动指针,只有一个线程可以移动成功,移动失败的线程重试,直到成功为止
- TLAB (thread local Allocation buffer):也称为本地线程分配缓冲,这个处理方式思想很简单,就是当线程开启时,虚拟机会为每个线程分配一块较大的空间,然后线程内部创建对象的时候,就从自己的空间分配,这样就不会有并发问题了,当线程自己的空间用完了才会从堆中分配内存,之后会转为通过 CAS+重试机制来解决并发问题
以上就是虚拟机解决对象内存分配时存在的线程安全问题的措施。
2.3、初始化零值
初始化零值,顾名思义,就是对分配的这一块内存初始化零值,也就是给实例对象的成员变量赋于零值,比如 int 类型赋值为 0,引用类型为null等操作。这样对象就可以在没有赋值情况下使用了,只不过访问对象的成员变量都是零值。
2.4、设置头对象
初始化零值完成之后,虚拟机就会对对象进行必要的设置,比如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息,这些信息都会存放在对象头中。这部分数据,官方称它为“Mark Word”。
在 HotSpot 虚拟机中,对象在内存中存储的布局可以分为 3 块区域:对象头 (Header)、 实例数据 (Instance Data) 和对齐填充位 (Padding)。
以 32 位的虚拟机为例,对象的组成可以用如下图来简要概括。(64位的虚拟机略有不同)
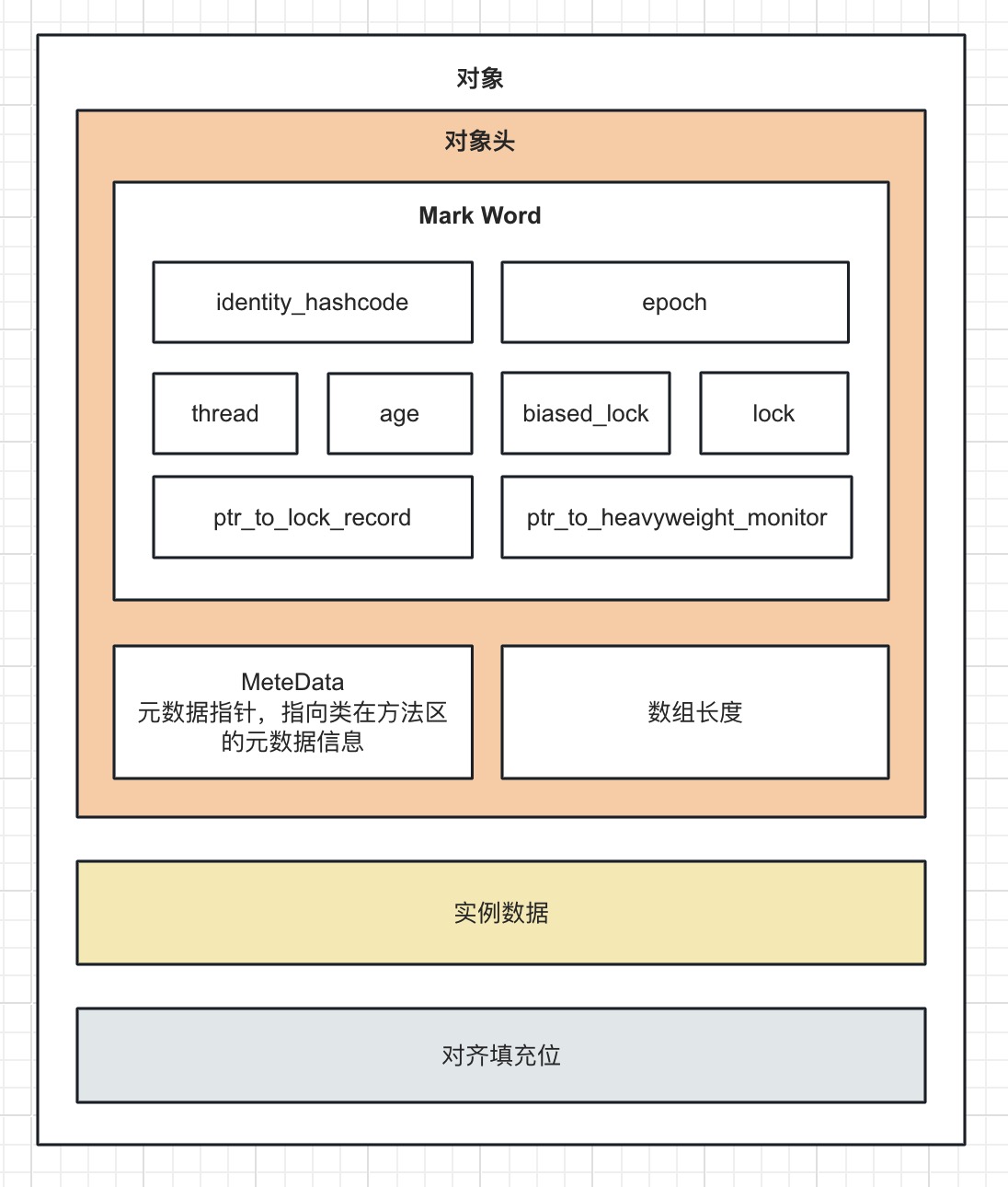
各部分区域功能如下:
- 对象头:分为 Mark Word 和元数据区,如果是数组对象,还有记录数组长度的区域。这三块保存着对象的 hashCode 值,锁的状态,类元数据指针,对象的分代年龄等等信息。
- 实例数据:顾名思义,用于保存对象成员变量的值,如果变量是引用类型,保存的是内存地址
- 对齐填充位:因为 HotSpot 虚拟机要求对象的起止地址必须是 8 字节的整数倍,也就是要求对象的大小为 8 字节的整数倍,如果不足 8 字节的整数倍,那么就需要通过对齐填充进行占位,补够 8 字节的整数倍。
我们重点来看下 Mark Word 的组成,不同的操作系统环境下占用的空间不同,在 32 位操作系统中占 4 个字节,在 64 位中占 8 个字节。
以 32 位操作系统为例,Mark Word 内部结构如下:
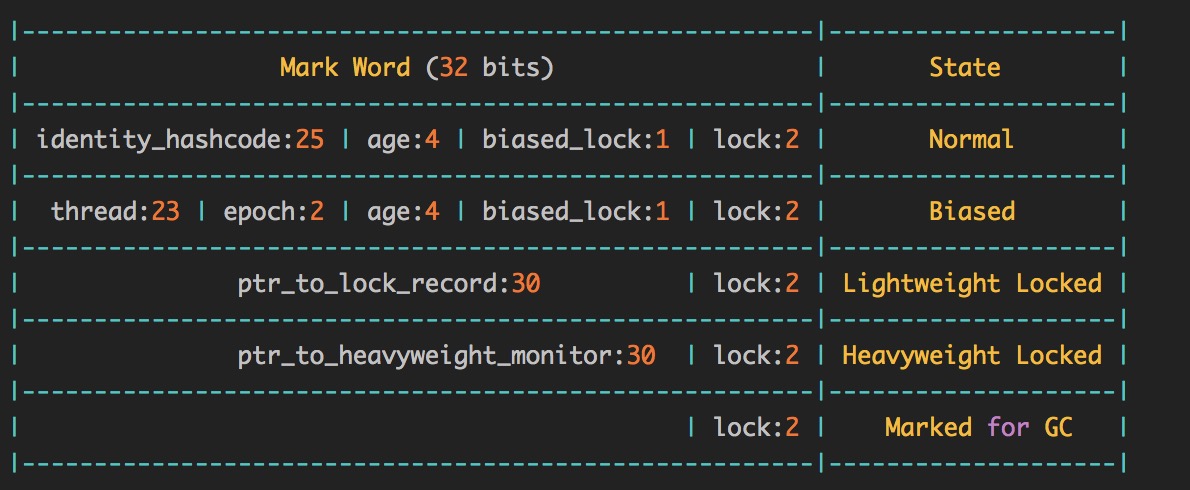
各部分的含义如下:
- identity_hashcode:25 位的对象标识哈希码。采用延迟加载技术,调用
System.identityHashCode()方法获取,并会将结果写到该对象头中。当对象被锁定时,该值会移动到管程 Monitor 中。 - age:4 位的 Java 对象年龄。在GC中,如果对象在 Survivor 区复制一次,年龄增加 1,当对象达到设定的阈值时,将会晋升到老年代。默认情况下,并行 GC 的年龄阈值为 15,并发 GC 的年龄阈值为 6。由于 age 只有4位,所以最大值为15,这就是为什么
-XX:MaxTenuringThreshold选项最大值为 15 的原因。 - lock:2 位的锁状态标记位。对象的加锁状态分为无锁、偏向锁、轻量级锁、重量级锁等几种标记,不同的标记值,表示的含义也不同。
- biased_lock:对象是否启用偏向锁标记,只占 1 个二进制位。为 1 时表示对象启用偏向锁,为 0 时表示对象没有偏向锁。偏向锁是一种锁的优化手段,开启偏向锁,某些时候可以省去线程频繁申请锁的操作,提升程序执行性能。
- thread:持有偏向锁的线程 ID,如果该线程再次访问这个锁的代码块,可以直接访问
- epoch:偏向锁在 CAS 锁操作过程中的标识
- ptr_to_lock_record:在轻量级锁时,指向栈中锁记录的指针
- ptr_to_heavyweight_monitor:在重量级锁时,指向管程 Monitor 的指针
其中lock参数中不同的标记值,表示的含义如下。

lock标记位,通常会在使用到synchronized关键字的对象上发挥作用。随着线程之间竞争激烈程度,对象锁会从无锁状态逐渐升级到重量级锁,其中的变化过程,可以用如下步骤来概括。
- 1.初期锁对象刚创建时,还没有任何线程来竞争,锁状态为 01,偏向锁标识位是0(无线程竞争它),此时程序执行效率最高。
- 2.当有一个线程来竞争锁时,先用偏向锁,表示锁对象偏爱这个线程,这个线程要执行这个锁关联的任何代码,不需要再做任何检查和切换,这种竞争不激烈的情况下,效率也非常高。
- 3.当有两个线程开始竞争这个锁对象时,情况会发生变化,锁会升级为轻量级锁,两个线程公平竞争,哪个线程先占有锁对象并执行代码,锁对象的 Mark Word 就执行哪个线程的栈帧中的锁记录。轻量级锁在加锁过程中,用到了自旋锁。所谓自旋,就是指当有另外一个线程来竞争锁时,这个线程会在原地循环等待,而不是把该线程给阻塞,直到那个获得锁的线程释放锁之后,这个线程就可以马上获得锁,执行效率有所衰减。
- 4.如果竞争这个锁对象的线程越来越多,会导致更多的切换和等待,JVM 会把该对象的锁升级为重量级锁。这个就是大家常说的同步锁,此时对象中的 Mark Word 会再次发生变化,会指向一个监视器 (Monitor) 对象,这个监视器对象用集合的形式来登记和管理排队的线程。Monitor 依赖操作系统的 MutexLock(互斥锁)来实现线程排队,线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换线程,相比其它级别的锁,此时锁的性能最差。
关于synchronized关键字原理分析,我们会在后续的文章中再次介绍。
2.5、执行init方法
执行 init 方法是对象创建的最后一步,虚拟机会给对象的成员变量设置用户指定的初始值,并且会执行构造方法等。
2.6、小结
以上就是对象的创建过程,最后我们通过工具来看下对象创建后的大小。
可以添加第三方jol包,使用它来打印对象的内存布局情况。
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>编写一个测试类。
public class ObjectHeaderTest {
public static void main(String[] args) {
System.out.println("=========打印Object对象的大小========");
ClassLayout layout = ClassLayout.parseInstance(new Object());
System.out.println(layout.toPrintable());
System.out.println("========打印数组对象的大小=========");
ClassLayout layout1 = ClassLayout.parseInstance(new int[]{});
System.out.println(layout1.toPrintable());
System.out.println("========打印有成员变量的对象大小=========");
ClassLayout layout2 = ClassLayout.parseInstance(new ArtisanTest());
System.out.println(layout2.toPrintable());
}
/**
* ‐XX:+UseCompressedOops 表示开启压缩普通对象指针
* ‐XX:+UseCompressedClassPointers 表示开启压缩类指针
*
*/
public static class ArtisanTest {
int id; //4B
String name; //4B
byte b; //1B
Object o; //4B
}
}输出结果:
=========打印Object对象的大小========
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
========打印数组对象的大小=========
[I object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 6d 01 00 f8 (01101101 00000001 00000000 11111000) (-134217363)
12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
16 0 int [I.<elements> N/A
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
========打印有成员变量的对象大小=========
com.example.thread.o4.ObjectHeaderTest$ArtisanTest object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 12 f2 00 f8 (00010010 11110010 00000000 11111000) (-134155758)
12 4 int ArtisanTest.id 0
16 1 byte ArtisanTest.b 0
17 3 (alignment/padding gap)
20 4 java.lang.String ArtisanTest.name null
24 4 java.lang.Object ArtisanTest.o null
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 3 bytes internal + 4 bytes external = 7 bytes total三、对象的访问方式
对象创建完之后,剩下的工作就是使用对象。Java 程序主要通过虚拟机栈上的 reference (引用) 数据来操作堆上的具体对象。
对象的访问方式有虚拟机实现而定,不同的虚拟机实现访问方式不同,目前主流的访问方式有:
- 句柄访问
- 直接指针访问
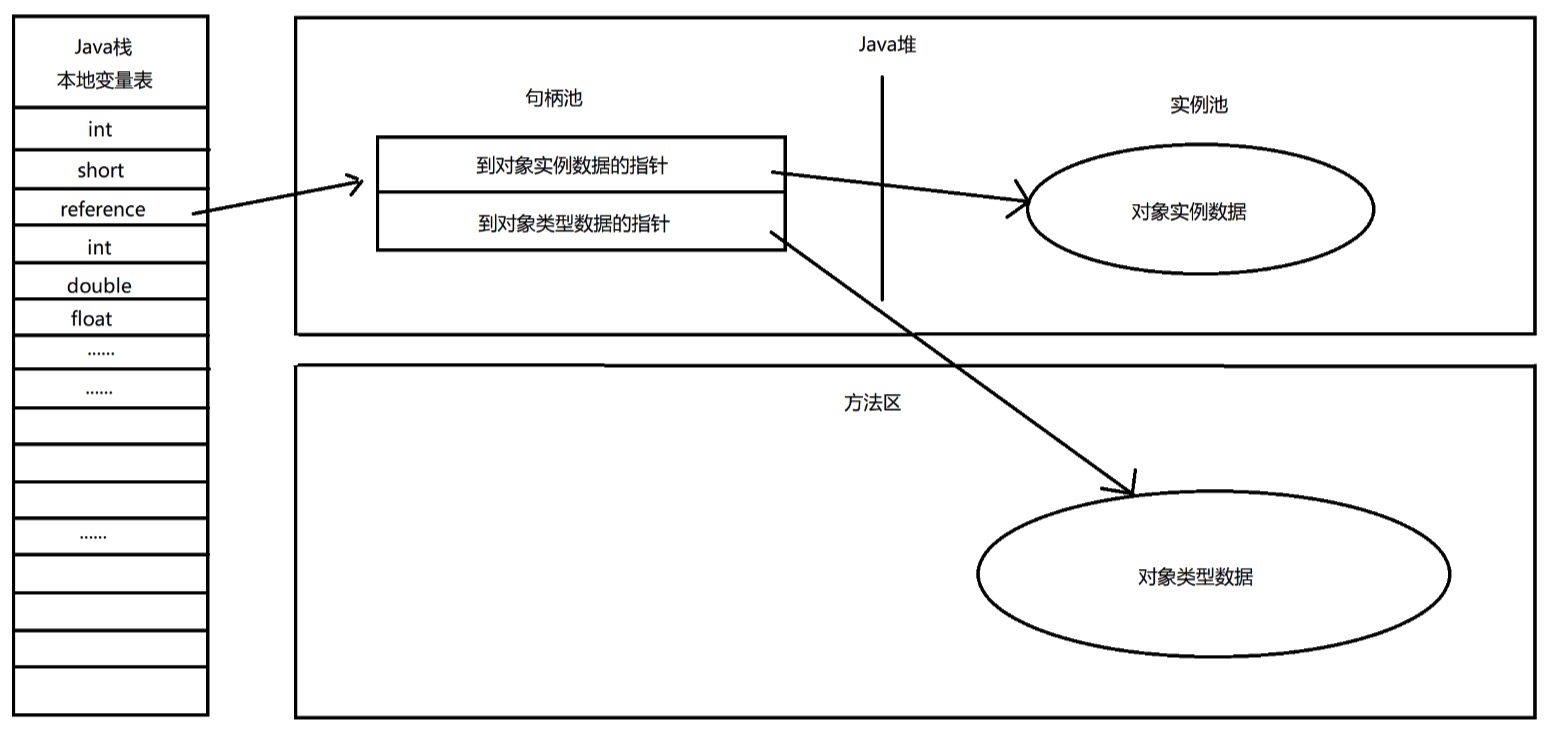
3.1、句柄访问
句柄访问,虚拟机会在 Java 堆中划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,句柄中则包含了类数据的地址和实例数据的地址信息。
使用句柄方式最大的好处就是,reference 中存储的是稳定的句柄地址,在对象被移动时(垃圾收集时移动对象是非常普遍的行为),只会改变句柄中的实例数据指针,而 reference 不需要被修改。
3.2、直接指针访问
直接指针访问,reference 中直接存储的就是对象地址,而对象中存储了所有的实例数据和类数据的地址。
使用直接指针方式,最大的好处就是速度更快,它节省了一次指针定位的时间开销。
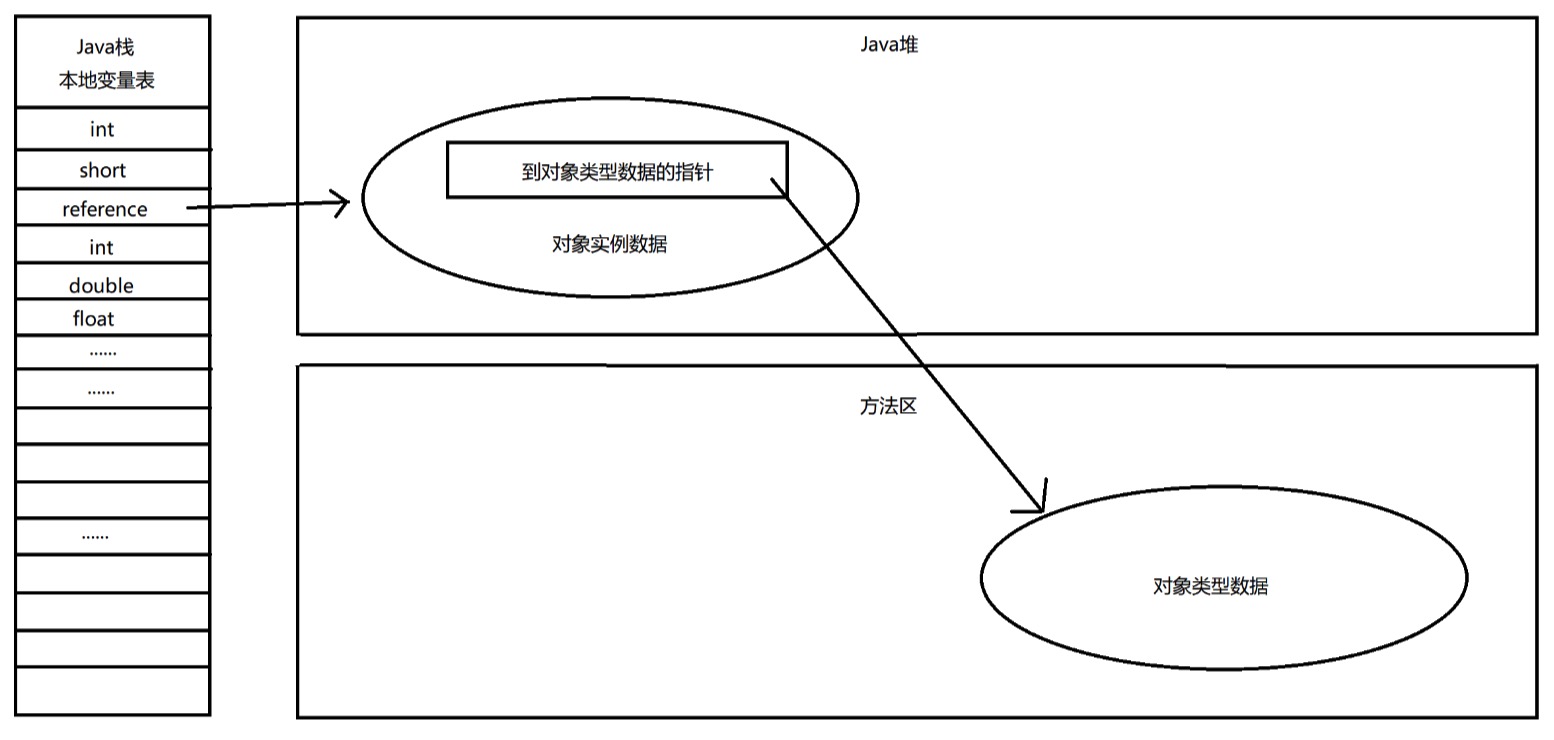
就 HotSpot 虚拟机而言,它使用的是直接指针访问方式来定位对象,从其它虚拟机实现来看,使用句柄访问方式也是十分常见的。
四、小结
本文主要从虚拟机层面,对对象的创建过程,访问方式进行了一次知识整合和总结,如果有描述不对的地方,欢迎大家留言指出。
五、参考
1.https://zhuanlan.zhihu.com/p/267223891
2.https://zhuanlan.zhihu.com/p/401057707
3.https://www.cnblogs.com/xrq730/p/4827590.html
4.https://www.jianshu.com/p/3d38cba67f8b
6.https://blog.csdn.net/clover_lily/article/details/80095580
7.https://blog.csdn.net/FIRE_TRAY/article/details/51275788
8.https://blog.csdn.net/yb970521/article/details/108015984
作者:潘志的技术笔记
出处:https://pzblog.cn/
版权归作者所有,转载请注明出处
